AWS
This post is about the deployment of little-ecom (a microservices-based ecommerce api) on AWS. I’ll talk about the problems I faced and how I solved them.
Knowing AWS: EC2 vs ECS
While EC2 provides resizable compute capacity in the cloud, ECS is a container orchestration service. Deploying on EC2 instances through ECS offers more control over the host infrastructure compared to using AWS Fargate, which abstracts the server management.
Creating ECS Cluster
In this step, I selected the instance type, VPC, and security groups, which define the network and security settings. The operating system and architecture are determined by the chosen AMI. To manage costs, I opted for t2.micro instances within the free tier.
Load Balancer and Target Groups
A load balancer distributes incoming traffic across multiple targets in a target group, improving fault tolerance. Target groups manage where to route traffic for the load balancer, and each ECS task can be registered as a target. Tasks are like a pod in Kubernetes in terms of container grouping.
ECR
ECR is a managed Docker container registry for storing, managing, and deploying container images. Creating a repository in ECR is a prerequisite to image pushing, unlike Docker Hub, where repositories are created on the first push. Special AWS authentication is required to push images to ECR.
Task definition and Service
A task definition is where you create a template of a single task, which images it uses, opened ports, expected RAM/CPU usage… A service on the other hand defines how many tasks you want to run over your instances, load balancers to distribute traffic across those different tasks, the subnets and vpc you wish to run your tasks and other options.
RDS and AWS Network Infrastucture
RDS is the Relational Database Service from AWS. I had to create a postgres instance to store user credentials since auth service uses it. However, the hardest thing was that after I created it I didn’t mark it as public so this instance was running privately under AWS infrastructure, but also I didn’t have the key pairs to access it through ssh. How did I get rid of this situation? Consider that I needed to access it to create tables, users and those things.
Well, in scenarios like these (which are pretty common) you can use another ec2 instance that can be accessed from the internet but yet lies on the same VPC that RDS is using. I tried to use ECS cluster’s instance, but I didn’t mark allow ssh option as true when creating the cluster. So instead, I did these steps:
1- I created another instance under the same RDS Virtual Private Cloud
2- Allowed it to be accessible from outside world
3- Allowed TCP connection on port 22 for SSH
4- Downloaded it’s key value pair
5- Deployed it
6- On my host machine I did:
1
ssh -i private_key.pem ec2_user@186.x.y.z
And boom. I was inside this instance, now I could in theory access my RDS instance. Then:
- ` ping 172.x.y.z (consider this was my RDS private’s IP) Nothing happened.
I wasn’t able to get connections because I first had to access the RDS security group to make the instance security group allow connections in port 22. I guess it was only accepting inbound connections from itself.
Then, in this instance I installed the postgres package which gives me the capability to call psql which allows me to make remote connections with a postgres database. Since AWS uses Red-hat based distribution:
sudo yum install postgresql12 -ythen:psql -h 10.x.y.z -U …
And boom. It worked! Now it’s good to reflect on what happened, because a very complex and important topic on AWS has arised and if we don’t solidly grasp it we’ll soon get lost. What I did is called “bastion host”, because a machine was intermediating the connection and in some sense it was protecting an RDS instance. Why? Because I didn’t have to expose it publicly on the internet but still I was able to access it somehow.
So RDS has some kind of layer protecting him. I like to think about it like Gandalf’s protecting the Ring’s society from a giant beast. In our case Gandalf’s was this ec2 instance. Everything that is directly on the internet can have attacks, tons of requests, vulnerabilities and so on.
AWS Network Infrastructure
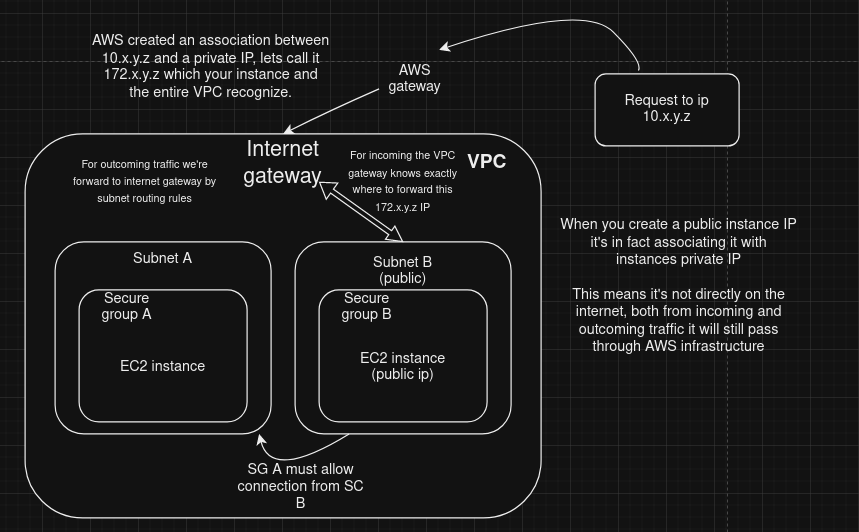
This situation I described showed to me I needed to learn more about how this process was working. Because, think with me, how the heck do our instance have a public IP but still run under a VPC context which only has private instances? What happen is, our instance doesn’t have a public IP even if I could directly access it.
In fact, AWS keeps track of an association between a unique public IP address and your instances private ip so when you send a request to some ip like 10.x.y.z it reach at AWS gateway, then AWS knows it’s from 172.x.y.z (yeah it’s really a NAT that’s happening), then it’s redirected to VPC, then VPC has routing rules to redirect it to appropriate subnet which your instances live.
Here in this diagram you can visualize this flow happening
Auth deployment: Secret manager and AWS SDK
In my previous k8s little-ecom implementation I was using environment variables to get database credentials, but to be more professional this time with ECS I deployed a Secret Manager on my VPC. Then, in my auth service’s image I used aws sdk to communicate with the secret manager’s service and retrieve credentials.
It was pretty easy to be honest. Then, I deployed a new revision and started to work on the ecs auth service to launch the task definition. It wasn’t launching, in fact some error was happening. Amazon circuit breaker was failing the deployments but no useful log was being shown. I had to break my head on this.
The circuit breaker was not even letting the log appear before shutdown everything so I disabled it. Then, I went to cloudwatch and in fact it showed some out of resources problems. The task definition was asking for more memory than a single-instance could offer. Then I decreased it. It worked and now I could even visualize the memory available being decreased under container instance spec.
But now another error arises. My task wasn’t being able to connect with the secret manager. First, I checked if VPC actually has an internet connection and yeah it does, then I checked both security groups from instance-level and task-level both were allowing every type of connection. Then, I thought maybe the task role wasn’t allowing me to make the connection.
In AWS a task definition will ask you for a task role and task execution role. The difference: Task role: A task role defines what services your application can use, the actually running container, it was set to none so this could be the problem Task execution role: A task execution role defines what the ECS agent/task executor (which will run your container) can do. I don’t know if it’s the most accurate meaning but it’s more related to things that manage your application and not your application itself.
I’ve allowed a lot of policies for both options but none of these were the solution. Then, I tried to use AWS exec to join inside the task using a terminal to test connections but I had to create a new policy to make it work. AWS Systems Manager is required to make exec work and also an AWS session manager.
After running
1
2
3
4
5
6
7
8
aws ecs execute-command \
--region sa-east-1 \
--cluster little-ecom-main-cluster \
--task 8ef2a71e183c40ec97b48231fea2639e \
--container auth \
--command "/bin/sh" \
--interactive
It didn’t work. I guess the reason was my task was getting down right after the connection timeout so I wasn’t able to join inside the task. Imagine how much time I was wasting on this problem.
Well, at the end of the internet some random dude was getting the same problem he said creating an internal endpoint VPC was the solution. An in fact it was, let me explain what a VPC endpoint is:
Usually you don’t want your services accessing the public internet since you would have to expose instances and send data traffic to outside your cluster, also having to traverse the internet may increase latency. Since AWS knows that and generally you will use their services a lot they introduced a way of allocating their services close to you in your private VPC.
If you choose an interface VPC endpoint it will use a combination of ENI (elastic network interface) which will manage IPs, route tables, MAC addresses… “gluing” it with your VPC with the service you choose to have available locally.
Now another problem arises again (I’m becoming nuts). I was running out of ENI resources on my instances, but I solved them quickly just by increasing auto-scaling. Then again, my tasks weren’t running for that long. I figured out health checks were failing and of course they did since I didn’t have created an auth endpoint.
So I created this endpoint. Published to ECR, New task revision, update service and…
Finally my authentication service was available on the internet.
Backend deployment
I’ve deployed authentication service first because little-ecom’s backend service uses it to validate tokens, but what my backend also uses is a mongo database to store and handle products. Instead of self-hosting a MongoDB on AWS I used DocumentDB which is mongo compatible.
Then, I’ve also managed to create a secret using Secret Manager to store credentials and connection-related things, and used AWS sdk in backend service’s code to retrieve and connect with the document db. Deployed ECR, new task revision, then I realized I forgot to give task role permission to use AWS services. Update again, deploy…
Error: without ENI resources again. This time I chose another path to solve it. Instead of use awsvpc network type for the task (which uses ENI to allocate network configuration for it on the vpc) I changed to host type, which keeps listening on the instance port. But of course it wouldn’t work at first.
In fact, I also had to change the target group to point to instances instead of IPs. Then, what I think that happens is: when the service launches a task, it also informs the target group about which instances it is, since the target group knows he was configured for instances and which port tasks will be launched it knows who are the targets so the load balancer can come and send requests to them.
Finally, the deploy had worked. But I missed something, when sending requests to it I saw validateToken wasn’t working and of course it doesn’t, I was using k8s dns domain to send requests from backend to auth. I forgot to update it to the aws url. Then, after updated, everything worked properly.
Conclusion
That wasn’t easy, but I learned a lot through this project. Especially about the descentralized way AWS works. I mean, you have services, instances, tasks, target groups, task definitions, vpc, subnets, load balancers… they all serve for different purposes but coordinate together to build a very robust application.
They should be small, each task should be a microservice that you can deploy alone and they only need to depend on some environment variables and secrets. Everything is an API and that’s great, you don’t have to rely on executables or binaries that can crash and are coupled.
It’s also a reminder of why kubernetes or terraform are good. See how much work I had just for AWS but for instance I have several options (aws, gcp, azure) and also my steps weren’t in a common sense reproducible, manually I had to do a lot of things. Kubernetes and terraform can rescue in this situation, but of course it is always good to know a specific service like ECS.
Another cool thing was the way AWS gives you the power of everything: instances, scaling, subnets and all those things. It’s hard to setup, but since cloud world is growing more and more it makes sense how we have that many features. Hope you have a good day!